



I. Présentation ♪▲
Tout site qui se veut complet et qui comporte beaucoup d'informations se doit d'avoir une fonctionnalité de recherche simple d'utilisation et performante.
Les pages de recherche doivent être simples, un peu à l'image de Google. L'interface est minimale avec un simple champ pour y mettre les critères, un bouton et de simples textes en résultats. La rapidité de la réponse est plus importante que la mise en page des résultats dans ce type de page.
Cette recherche s'appuie sur Sql Server pour ce qui est de la base de données. Dans ce document, nous allons voir la manière d'implémenter cette recherche au sein de la version 8.0 de Sql Server, plus connue sous le nom de Sql Server 2000. Sql Server 2005 a gardé le même moteur d'indexation fulltext.
II. Définition du terme « Full-Text »▲
La technologie full-text permet de créer des index sur base de mots non parasites et d'utiliser ces index pour des recherches (avec support linguistique) ainsi que des recherches de proximité.
Il est important de comprendre ces trois définitions conceptuelles pour réellement saisir le fonctionnement de cette technologie.
Les mots parasites sont les mots de liaison, les pronoms… tels que « je », « de », « car » et bien d'autres. Ceci permet d'éviter d'avoir comme résultat des données faussées par ces mots. Ainsi, si l'on effectue une recherche avec comme critère la phrase « je veux une classe mfc qui permet de faire du gdi », seuls les mots « classe », « mfc » et « gdi » seront pris en compte.
Le support linguistique permet de définir, en interne, toute une série de mots qui dérivent de ceux qui forment les critères. Ainsi, pour le mot « nager », le système effectuera la recherche avec les mots « nager », « nage », « nagé(e) ».
La recherche de proximité permet de spécifier qu'un mot doit se trouver près d'un autre. Dans le cas de SqlServer, il s'agit d'un « rayon » de 50 mots. Ce nombre est fixé et n'est pas paramétrable.
On notera que Sql Server est très proche de la norme SQL:1999 Module Multimédia (MM).
III. Historique du Full-Text dans Sql Server▲
Cette fonctionnalité est apparue dans la version 7.0 de Sql Server. Le noyau utilisé par cette fonctionnalité est celui de Microsoft Search qui est également utilisé dans Microsoft Exchange et Microsoft SharePoint Portal Server.
Alors que dans la version 7.0, la recherche se limitait à des recherches de base, les performances, les index et les autres éléments nécessaires pour cette utilisation ont été revus dans la version 2000. Il est ainsi possible de faire des recherches dans des documents facilement.
Au travers de ce document, nous allons voir comment mettre en place la recherche full-text étape par étape en allant de la vérification de la présence du service jusqu'au questionnement.
IV. Concepts du Full-Text▲
Il existe quatre points fondamentaux par rapport à l'architecture full-text :
- gérer les définitions des tables et des colonnes qui sont enregistrées comme étant utilisés par les recherches full-text ;
- gérer la population des index ;
- effectuer les recherches ;
- mettre à jour les index (synchronisation).
Chacun de ces concepts est détaillé dans la suite du document séparément.
V. Architecture au sein de Sql Server▲
Comme on peut le voir sur le schéma qui suit, l'architecture est basée sur un service nommé Microsoft Search. Il s'agit du service qui gère l'indexation et la recherche au sein du full-text. Il comprend ainsi un moteur d'indexation et un moteur de recherche.
Ce service accède un catalogue d'index. Il s'agit en fait d'une série de fichiers qui ne se trouvent pas dans la base de données, mais bien dans le système de fichiers classique. Ce sont ces fichiers qui contiennent les différents mots de chaque ligne qui aura été préalablement indexée.
Il est primordial de garder en tête la scission entre les index classiques et les index full-text.
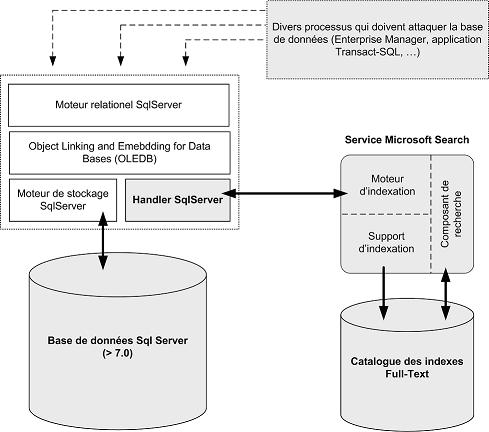
Le service Microsoft Search se charge de l'indexation full-text (il reçoit les informations, les trie, les classe…) ainsi que du questionnement.
Le dialogue entre Sql Server et le service se fait à l'aide d'un composant interne à Sql Server.
Avant l'arrivée de cette technologie, il était nécessaire d'utiliser un composant extérieur pour réaliser ces opérations, ce produit gérant les différents index au travers de fichiers enregistrés dans le système de fichiers classiques, rendant très difficile la combinaison d'une recherche full-text avec des requêtes relationnelles.
Pour exécuter Microsoft Search, il existe divers moyens :
- par le menu dans Enterprise Manager ;
- par le gestionnaire de services ;
- par la commande dos « net start mssearch » ;
- par le service manager de Sql Server.
Il n'y a qu'un service Microsoft Search par serveur. Celui-ci est installé si l'on en a fait la demande lors de l'installation de Sql Server.
Microsoft Search est à Sql Server ce qu'est Microsoft Indexing Service à Windows NT. Effectivement, MS Search permet l'indexation de textes alors que MS Indexing Service permet l'indexation des fichiers.
VI. Principe de l'indexation▲
Comme cela a déjà été signalé, les index ne sont pas stockés dans une base SqlServer, mais bien dans des fichiers qui sont gérés par le service. Il peut y avoir 256 catalogues d'index full-text par serveur.
C'est pourquoi, lors d'un backup ou d'une restauration, les catalogues permettant le full text ne sont pas pris en compte. Ce n'est d'ailleurs pas nécessaire vu que le catalogue peut être recréé (doit être recréé pour être plus précis) afin de tenir compte de toutes les nouvelles informations (et de celles qui sont effacées).
L'indexation des textes se fait de manière ponctuelle et non lors de chaque ajout, suppression ou modification de données ce qui permet d'éviter une détérioration des performances. Il faut également noter que le fait de ne pas indexer directement peut rendre les résultats d'une demande incomplets, voire incorrects, puisqu'ils se basent sur des données présentes à un moment t.
Comme on peut le voir, il y a de fortes différences entre les index classiques et les index full-text. Voici un petit récapitulatif des différences :
|
index classiques |
index full-text |
|---|---|
|
Stockés dans la base de données |
Stockés dans un fichier dans le système de fichiers |
|
Plusieurs index par table |
Un seul index par table |
|
Mis à jour automatiquement |
Mise à jour sur demande |
|
Manipulation par du SQL classique |
Manipulation par des procédures stockées |
|
Non groupés |
Groupés |
Lors d'une indexation, les valeurs de la colonne dont à indexer sont passés à Microsoft Search qui détermine les lignes à réindexer comme on peut le voir sur le schéma suivant :

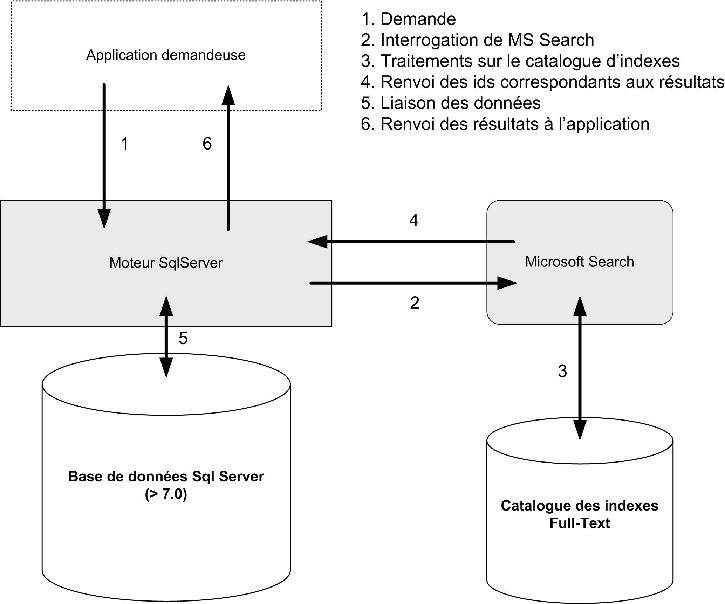
VII. Principe du questionnement▲
On ne cessera de le répéter, c'est bien le service Microsoft Search qui s'occupe du questionnement des index.
Les numéros des lignes correspondant aux critères sont envoyés du service à Sql Server qui se charge de faire la liaison entre les numéros de ligne et les données elles-mêmes.
Tout cela est résumé dans le schéma suivant :
VIII. Indexation full-text▲
Il faut avoir le rôle sysadmin ou db_owner pour la base spécifiée pour pouvoir exécuter ces procédures.
Voici les étapes une par une pour indexer selon le concept du full-text au sein de Sql Server :
Vérification
Il est possible de vérifier la présence du full-text à l'aide de la commande suivante :
select databaseproperty('nomdelabase' ,'IsFulltextEnabled');Activation du full-text
Si la commande précédente ne renvoie pas la valeur 1, il faut activer le full-text. Ceci se fait au niveau de la base par la commande :
use nomdelabase
exec sp_fulltext_database 'enable'Création du catalogue
La première chose est de créer un catalogue dans lequel seront stockés les différents index :
exec sp_fulltext_catalog 'nomducatalogueacreer', 'create'On ne cesse d'insister, mais il faut rappeler que le catalogue ne se trouve pas dans Sql Server lui-même, mais bien en tant que fichier dans le système de fichiers. L'interrogation du catalogue full-text requiert une forte activité d'entrée / sortie dans les fichiers. C'est pourquoi il est préférable de spécifier un disque physique différent de celui couramment utilisé pour y placer les fichiers contenant les catalogues.
La définition du répertoire de travail, si ce n'est celui par défaut, se fait lors de la création du catalogue, soit :
exec sp_fulltext_catalog 'nomducatalogueacreer', 'create', 'disque:\répertoire'Indexation d'une table
Chaque table qui comporte des colonnes à indexer pour la recherche full-text doit être signalée comme indexable. Pour cela, il est nécessaire, au préalable, d'avoir créé une clé primaire ou d'avoir une colonne pouvant prétendre être clé primaire, c'est-à-dire une clé unique, qui ne peut être « null » et sur une colonne unique.
L'appel à cette procédure a pour effet d'ajouter des métas informations dans les tables systèmes concernant le catalogue full-text ainsi que la table ajoutée.
Il n'y a aucune indexation qui ait été effectuée à ce moment.
exec sp_fulltext_table 'table', 'create', 'nomducataloguefulltext', 'nomcléprimaire'Indexation d'une colonne
L'ajout des colonnes à indexer est l'étape où il est nécessaire d'être le plus pointilleux. Effectivement, un mauvais paramétrage empêchera d'obtenir des résultats probants lors des recherches. Il est possible, par exemple, de spécifier la langue du contenu de la colonne. Sql Server s'en sert pour décliner certains mots. La ponctuation est différente d'une langue à l'autre également. Ce choix est donc très important. Dans le cas de la langue française, le code hexadécimal à passer comme paramètre est 0x040c. Si ce paramètre est omis, le choix se porte sur « neutre ».
La liste des mots parasites peut également être modifiée. Il est ainsi possible d'ajouter « br » comme un séparateur puisqu'il s'agit d'un séparateur pour l'HTML. Cette liste se trouve dans \Mssql\Ftdata\Sqlserver\Config.
Il est également possible de spécifier la langue par défaut pour la recherche full-text à l'aide de « sp_configure ».
L'appel à cette procédure ne crée toujours pas les index proprement dits, mais enregistre la colonne comme étant une colonne à indexer comme dans le cas des tables.
exec sp_fulltext_column 'table', 'colonne', 'add', 0x040cIndexation des valeurs
L'indexation peut se faire de plusieurs manières, cependant la syntaxe ne change pas.
L'indexation peut se faire sur une table
exec sp_fulltext_table 'table', 'start_full'ou sur tout le catalogue
exec sp_fulltext_catalog 'nomducatalogue', 'start_full'IX. Questionnement full-text▲
Nous l'avons vu dans le paragraphe consacré au principe du questionnement full-text, il faut lier les valeurs (les numéros de lignes) retournées par Microsoft Search avec celles contenues dans la base de données. Voici dès lors le type de requêtes à utiliser pour effectuer cela.
Il existe quatre prédicats qui permettent d'effectuer ces recherches : Contains, FreeText, ContainsTable et FreeTextTable. Ceux-ci sont décrits dans la suite de ce paragraphe.
L'utilisation de ces prédicats se fait uniquement sur des colonnes de type char, varchar, text, nchar, nvarchar, ntext.
Contains
Cette méthode renvoie 1 si la colonne spécifiée contient les mots ou phrases spécifiés comme critères. Il n'y a aucune notion de classement c'est pourquoi on l'utilisera que très peu si la pertinence des informations est importante.
Les critères peuvent être :
- un mot ou une phrase ;
- le préfixe d'un mot ou d'une phrase (*) ;
- un mot ou une phrase qui est proche d'une autre (NEAR ou ~).
WHERE CONTAINS(colonne, 'mot1 NEAR mot2')- un mot qui est un dérivé d'un autre (FORMSOF et INFLECTIONAL) :
WHERE CONTAINS(colonne, 'FORMSOF(INFLECTIONAL, mot)') ;- une série de mots ou de phrases qui ont un « poids » chacun (ISABOUT et WEIGHT) :
WHERE CONTAINS(colonne, 'ISABOUT (mot, mot, mot)')WHERE CONTAINS(colonne, 'ISABOUT (mot WEIGHT(.1), " mots " WEIGHT(.4), mot WEIGHT(.9)')Ce prédicat utilise, en interne, le « ContainsTable » qui sera décrit ci-dessous et effectue la jointure automatiquement. C'est pourquoi, principalement dans le cas d'une application Web, il est préférable d'utiliser ContainsTable quitte à ne pas utiliser toutes les informations retournées.
Elle effectue une recherche sur la correspondance exacte de tous les termes spécifiés dans la clause « critères ». Par rapport à FreeText qui sera présentée ci-dessous, la recherche en utilisant cette méthode est plus rapide. Il est cependant nécessaire d'effectuer un filtre sur les mots parasites sans quoi la recherche ne reverra aucun résultat lors de la recherche. Dans certains cas, le système peut même renvoyer une exception du type « Your query contains only noise words ».
Voici un exemple d'utilisation de ce prédicat. Comme on le voit, la syntaxe ressemble à celle utilisée par EXISTS.
SELECT colonne1
FROM table
WHERE CONTAINS(colonne2, 'mot')FreeText
Identique à « Contains » si ce n'est que l'on peut utiliser des phrases entières comme critères. Ces phrases peuvent être une phrase de tous les jours. C'est ici que le stemming (la déclinaison) prend forme.
Puisque la recherche est plus avancée que celle utilisée par Contains, les ressources processeur sont également plus utilisées. Le calcul du classement est plus sophistiqué également.
Il est tout de même important de noter que, malgré l'extrême complexité de ce type de recherche, elle reste tout de même très rapide. Une recherche sur quelques milliers de lignes indexées donne un résultat en moins d'une seconde.
Généralement c'est l'utilisation de cette méthode qui est choisie dans le cadre d'une application web.
SELECT colonne1
FROM table
WHERE FREETEXT(colonne2, 'phrase complete avec des virgules, des points et des mots parasites.')ContainsTable
Les paramètres sont identiques à ceux du prédicat CONTAINS. Ce prédicat renvoie une table contenant différentes informations qui sont principalement la clé qui est utilisée pour faire le lien entre les données indexées et les données stockées dans la base de données et le classement de cette ligne.
SELECT Extern_Table.colonne, Key_Table.RANK
FROM table AS Extern_Table
INNER JOIN CONTAINSTABLE(table, colonne, 'mot1 AND mot2' ) AS Key_Table
ON Extern_Table.colonneID = Key_Table.[KEY]
ORDER BY Key_Table.RANK DESCFreeTextTable
Les paramètres sont identiques à ceux du prédicat FREETEXT.
Pour ce qui est des colonnes de la table de retour, elles sont identiques à celle renvoyée par ContainsTable.
Il s'agit du prédicat généralement utilisé lors des recherches sur le web. Il est moins restrictif que ContainsTable, mais est légèrement plus lente. Ce prédicat permet surtout des recherches plus intuitives.
SELECT Extern_Table.colonne, Key_Table.RANK
FROM table AS Extern_Table
INNER JOIN FREETEXTTABLE(table, colonne, 'critères' ) AS Key_Table
ON Extern_Table. colonneID = Key_Table.[KEY]
ORDER BY Key_Table.RANK DESCX. Classement d'un résultat▲
Les résultats des recherches sont classés, si l'on a utilisé ContainsTable ou FreeTextTable, afin de savoir lequel des résultats est le plus pertinent.
Parmi les différents facteurs intervenant dans le calcul du classement, on peut noter entre autres la fréquence du mot dans un champ. Un autre facteur est le nombre total d'occurrences du mot dans la table.
Le classement est relatif. Ceci signifie que le classement d'une ligne peut être modifié suite à la modification des valeurs d'une autre ligne.
Étant donné que les classements sont relatifs sur une table uniquement, il pourrait être avantageux de créer une table supplémentaire contenant les informations à indexer en faisant cependant attention à la cohérence des informations.
XI. Paging de résultats▲
Le paging de résultats consiste à afficher un certain nombre de résultats à l'écran et permettre la navigation vers d'autres pages contenant la suite des résultats.
Il n'existe aucune méthode efficace à 100 % pour effectuer du paging au travers de résultats d'une telle procédure. Effectivement, les classements peuvent être modifiés suite à une modification des valeurs ou simplement des résultats de même classement peuvent se trouver inversés d'une requête à l'autre. Ainsi, on pourrait se trouver face la situation pareille : des résultats se trouvent dans la deuxième page de résultats lors de l'affichage de la première page et inversement.
De nouveau, ceci se comprend aisément si l'on garde bien à l'esprit la séparation des index full-text et des données.
Parmi les solutions les plus efficaces, on peut citer la mise en cache des informations afin d'éviter les différentes requêtes. Cela a deux avantages : les données seront toujours visibles dans le même ordre et il n'est pas nécessaire d'effectuer plusieurs requêtes, ce qui diminue les temps de réponse.
Une autre solution serait d'utiliser une table temporaire. Dans ce cas, l'ordre des éléments ne sera pas modifié d'une requête à l'autre sauf si cette table est mise à jour.
XII. Indexation d'un catalogue▲
Nous allons considérer que le catalogue full-text a été créé. Si ce n'est pas le cas, il est conseillé d'effectuer les étapes décrites dans le paragraphe intitulé « Activation du full-text ».
Indexation complète
L'indexation de toutes les lignes de toutes les tables que l'on a signalées comme indexables se fait une seule commande. Cette commande supprime tous les index et réindexe entièrement les valeurs.
exec sp_fulltext_catalog 'catalogue_fulltext', 'start_full'Indexation incrémentale
Contrairement à l'indexation complète, cette commande permet d'indexer uniquement les lignes qui ont subi un changement. Il faut pour cela qu'une colonne de type timestamp soit présente dans chacune des tables à indexer.
exec sp_fulltext_catalog 'catalogue_fulltext', 'start_incremental'Arrêt de l'indexation
Il est possible d'arrêter l'indexation en cours. Ceci est utile principalement si l'on se rend compte que cette indexation consomme trop de ressources processeur.
exec sp_fulltext_catalog 'catalogue_fulltext', 'stop'XIII. Indexation d'une table▲
De nouveau, nous considérons que la table sur laquelle nous voulons effectuer ces commandes est bel et bien signalée comme indexée.
Indexation complète
Il est possible d'indexer toutes les lignes de la table en une commande. Celle-ci supprime tous les index et réindexe entièrement les valeurs.
exec sp_fulltext_table catalogue_fulltext, 'start_full'Indexation incrémentale
Contrairement à l'indexation complète, cette commande permet d'indexer uniquement les lignes qui ont subi un changement. Il faut pour cela qu'une colonne de type timestamp soit présente dans la table à indexer.
exec sp_fulltext_table catalogue_fulltext, 'start_incremental'Arrêt de l'indexation
Comme pour le catalogue, il est possible d'arrêter l'indexation en cours.
exec sp_fulltext_table catalogue_fulltext, 'stop'Indexation incrémentale et tracking
Le tracking permet d'enregistrer les changements effectués sur la table. Cet enregistrement ne s'effectue pas sur les colonnes de type image, ntext et text.
Cette commande effectue tout d'abord une indexation incrémentale avant de démarrage l'enregistrement. S’il n'y a pas de colonne de type timestamp, une indexation complète est effectuée.
exec sp_fulltext_table 'catalogue_fulltext, 'start_change_tracking'Arrêt du tracking
La commande pour arrêter le tracking est la suivante.
Propagation des changements enregistrés aux index
L'enregistrement des changements de valeurs n'effectue pas la mise à jour des index de manière automatique. Il est nécessaire de spécifier qu'il faut propager ces changements aux index. Ceci se fait à l'aide de :
exec sp_fulltext_table 'catalogue_fulltext, 'update_index'Propagation automatique des changements
Il est possible de spécifier que les changements de valeurs doivent être répercutés le plus rapidement possible dans les index.
Ceci est utile si les nouvelles données doivent apparaître dans les résultats d'une recherche rapidement après leur mise à jour.
exec sp_fulltext_table 'catalogue_fulltext, 'start_background_updateindex'Arrêt de la propagation automatique des changements
Pour arrêter cette propagation automatique
exec sp_fulltext_table 'catalogue_fulltext, 'stop_background_updateindex'XIV. Conseils d'utilisation▲
Ces quelques conseils sont extraits de la documentation msdn ou sont basés sur des tests personnels.
Emplacement des fichiers
L'indexation full-text portant sur des tables comportant moins d'un million de lignes ne nécessite aucune optimisation ou presque. Si le nombre de lignes est supérieur au million, il est nécessaire configurer Sql Server afin de favoriser les performances entrées/sorties vers les fichiers utilisés. Comme souvent, il est préférable de mettre les fichiers sur un disque physique distinct de celui utilisé par Sql Server lui-même.
Sous Windows 2000, le pagefile.sys doit être 1,5 à 2 fois plus grand que la taille de la mémoire. De nouveau, ce fichier doit se trouver sur un autre disque que ceux utilisés par Sql Server, l'environnement hôte et le catalogue si cela est possible.
Configuration machine
Bien entendu, la configuration machine a une très grande importance. L'utilisation de multiples processeurs, d'un maximum de mémoire vive, de différents disques et la mise en RAID permettent d'augmenter significativement les performances.
Type d'indexation
Dans le cas d'une indexation sur un grand nombre de lignes, il est préférable d'utiliser le mode « Change Tracking » ou encore la population incrémentale des index en lieu et place de la population complète.
Selon la documentation msdn, la mise à jour complète des index sur des tables comportant de 4 à 20 millions de lignes de données peut prendre des heures, voire des jours. Pour 20 millions, une centaine d'heures peuvent être nécessaires.
Périodicité de l'indexation
La mise à jour des index doit s'effectuer lors d'une période de basse activité pour le serveur, c'est-à-dire généralement la nuit. Il faut cependant faire attention que la nuit pour certains signifie le jour pour d'autres si l'application est utilisée dans différents pays.
Nombre de valeurs de retour
Dans le cas d'une recherche, ce qui est généralement l'utilité de l'indexation full-text, il est rarement nécessaire de retourner des milliers de lignes de résultats à l'utilisateur. La plupart des données ne lui seront d'aucune utilité, il est dès lors bon de limiter le nombre de valeurs retournées lors de l'appel des procédures.
Par ailleurs, il est bon d'utiliser le mot clé « TOP », qui limitera le nombre de lignes retournées à la valeur fixée lors de la requête, afin d'améliorer les performances.
De plus, il est nécessaire d'utiliser le mot clé « WHERE » après la jointure et non avant.
Approximativement, une recherche full-text à partir du web qui s'effectue sur plusieurs millions de lignes peut prendre de 20 à 30 secondes si l'on utilise CONTAINS et FREETEXT.
Recherche dans toutes les colonnes d'une table
Si une recherche doit s'effectuer sur toutes les colonnes d'une table, il est préférable d'utiliser « * » au lieu de boucler et d'effectuer la recherche sur chaque colonne de la table. Ceci permet de réduire le coût en temps.
XV. Procédures stockées personnelles permettant la recherche full-text▲
Table contenant les id
Vu la lenteur de la procédure sp_fulltext_columns (une moyenne de 9 secs était nécessaire lors des différents tests), une table supplémentaire est présente au sein même de la base. Cette table ne contient que des données redondantes par rapport aux données stockées dans le catalogue d'indexation full-text. Elles sont cependant plus simples d'utilisation puisqu'il s'agit d'une simple table relationnelle.
Elle contient comme informations les id des tables et des colonnes indexées comme on peut le voir dans la définition de la table :
CREATE TABLE fulltext_indexedcolumns
(
column_id INTEGER,
column_name SYSNAME,
table_id INTEGER,
table_name SYSNAME
);Procédure de mise à jour des index
La table est mise à jour lors de l'appel de la procédure fulltext_generateIndex décrite ci-dessous. Cette procédure effectue par ailleurs la demande de mise à jour du catalogue d'index. La durée d'exécution de cette procédure est d'environ 9 secondes étant donné qu'elle utilise sp_fulltext_columns. Il est donc préférable de l'appeler de manière asynchrone.
CREATE PROCEDURE fulltext_generateIndex
AS
DECLARE
@cursor CURSOR,
@unused_table_owner SYSNAME,
@fulltext_colid INTEGER,
@table_name SYSNAME,
@table_id INTEGER,
@fulltext_column_name SYSNAME,
@unused_fulltext_blobtp_colname SYSNAME,
@unused_fulltext_blobtp_colid INTEGER,
@unused_fulltext_language SYSNAME
BEGIN
-- Bind the fulltext_indexedColumns table
DELETE FROM fulltext_indexedcolumns;
EXEC sp_help_fulltext_columns_cursor @cursor OUTPUT
FETCH NEXT FROM @cursor
INTO @unused_table_owner, @table_id, @table_name, @fulltext_column_name, @fulltext_colid,
@unused_fulltext_blobtp_colname, @unused_fulltext_blobtp_colid, @unused_fulltext_language
WHILE (@@FETCH_STATUS = 0)
BEGIN
INSERT INTO fulltext_indexedcolumns (Column_Id, Column_Name, Table_Id, Table_Name)
VALUES (@fulltext_colid, @fulltext_column_name, @table_id, @table_name);
FETCH NEXT FROM @cursor
INTO @unused_table_owner, @table_id, @table_name, @fulltext_column_name, @fulltext_colid,
@unused_fulltext_blobtp_colname, @unused_fulltext_blobtp_colid, @unused_fulltext_language
END
CLOSE @cursor
DEALLOCATE @cursor
-- Start full indexing
exec sp_fulltext_catalog 'fulltext_msdnacademiebe', 'start_incremental'
ENDTable d'informations sur les tables indexées
Le but de l'indexation full-text est, dans notre cas, d'effectuer des recherches. Ainsi, afin de recréer les liens vers les différentes pages du site, une table contient diverses informations telles que « quelle est la colonne qui sert de paramètre ? », « quelle est la page vers laquelle le lien doit pointer ? »… En voici sa structure :
CREATE TABLE fulltext_tables_infos
(
table_name SYSNAME,
rubric VARCHAR(25),
rubric_Link VARCHAR(25),
titleColumn VARCHAR(25),
titleLinkColumn VARCHAR(25),
descriptionColumn VARCHAR(25)
);Procédure d'ajout d'une colonne dans la liste des colonnes indexées
Afin d'être certain que les tables concernées par l'indexation aient été signalées comme indexables avant de faire l'ajout des colonnes, une procédure vérifie que la table est indexée avant d'indexer la colonne.
Il est nécessaire, pour effectuer l'indexation, que la table possède une clé prétendante au titre de clé primaire simple comme nous l'avons déjà vu. Le choix de cette clé unique doit se porter sur la clé la plus petite en taille. Dans le meilleur des cas, une clé utilisant 4 bytes, c'est-à-dire un integer, est optimale. Si la clé a une taille de plus de 100 bytes, il est fortement conseillé de modifier celle-ci ou d'ajouter une autre. De plus, si la clé est plus grande que 450 bytes, l'indexation ne pourra pas se faire.
CREATE PROCEDURE fulltext_addColumn
@table_name VARCHAR(50),
@column_name VARCHAR(50)
AS
DECLARE
@primaryKey_name VARCHAR(53)
BEGIN
IF OBJECTPROPERTY(OBJECT_ID(@table_name), 'TableFullTextCatalogId') = 0
BEGIN
SET @primaryKey_name = 'PK_' + @table_name;
exec sp_fulltext_table @table_name, 'create', 'fulltext_msdnacademiebe', @primaryKey_name
END
exec sp_fulltext_column @table_name, @column_name, 'add', 0x040c
ENDIl ne reste plus, dès lors, à appeler cette dernière procédure pour chaque colonne que l'on souhaite indexer.
exec fulltext_addColumn 'AspF_Messages', 'Item';
exec fulltext_addColumn 'Links', 'LinkName';
exec fulltext_addColumn 'Links', 'Description';
-- …Après avoir défini les différentes colonnes à indexer et il est possible d'effectuer des recherches à deux niveaux. Le premier niveau se situe au niveau d'une table. Cette recherche, suivant les valeurs des différents paramètres peut effectuer des opérations différentes. Il est ainsi possible de renvoyer directement les résultats ou de les insérer dans une table temporaire. Ce dernier cas est utilisé si la recherche porte sur toutes les tables indexées, ce qui est généralement le cas.
De plus, suivant les critères passés à la procédure, son comportement est différent. Soit elle fait appel à CONTAINSTABLE, soit à FREETEXTTABLE. Si aucun mot clé particulier tel que « AND », « OR »… c'est FREETEXTTABLE qui est utilisé.
CREATE PROCEDURE fulltext_search_table
@table_name VARCHAR(50),
@criterias NVARCHAR(4000),
@column_name VARCHAR(50) = NULL,
@useTempTable BIT = 0,
@largeScope BIT = 1,
@rowsToReturn INTEGER = -1
AS
BEGIN
DECLARE
@table_id INTEGER,
@unique_key_col_name SYSNAME,
@command NVARCHAR(4000),
-- Autres déclarations en VARCHAR(25)
-- Tests pour vérifier que tous les paramètres ont été passés correctement
SET @unique_key_col_name = Col_Name(@table_id, ObjectProperty(@table_id, 'TableFullTextKeyColumn'));
-- Vérification des mots clés dans les critères
-- Recuperation des noms de colonnes
SELECT @createCommand_title = titleColumn,
@createCommand_titleLink = titleLinkColumn,
@createCommand_titlePreLink = titlePreLinkText,
@createCommand_description = descriptionColumn,
@createCommand_rubricname = rubric
FROM fulltext_tables_infos
WHERE table_name = @table_name;
-- Test des valeurs retournées
SET @command = '';
IF @useTempTable = 1
BEGIN
SET @command = 'INSERT INTO #fulltext_results ';
END
-- SELECT
SET @command = @command + 'SELECT Extern_Table.' + @createCommand_title + ' AS Title, ';
SET @command = @command + '''' + @createCommand_titlePreLink + ''' + CAST(Extern_Table.' + @createCommand_titleLink + ' AS VARCHAR(20)) AS TitleLink, ';
SET @command = @command + 'SUBSTRING(Extern_Table.' + @createCommand_description + ', 1, 200) + '' (...)'' AS Description';
IF @useTempTable = 1
BEGIN
SET @command = @command + ', ''' + @createCommand_rubricname + ''', Key_Table.Rank ' ;
END
-- FROM
SET @command = @command + 'FROM ' + @table_name + ' AS Extern_Table INNER JOIN '
-- FREETEXT OU CONTAINS?
IF @largeScope = 1
BEGIN
SET @command = @command + 'FREETEXTTABLE';
END
ELSE
BEGIN
SET @command = @command + 'CONTAINSTABLE';
END
-- Parametres de l'appel
SET @command = @command + '(' + @table_name + ', ' + @column_name + ', ''';
-- Ajouter les criteres
SET @command = @command + @criterias + '''';
IF @rowsToReturn > -1
BEGIN
SET @command = @command + ', ' + CAST(@rowsToReturn AS VARCHAR(5));
END
SET @command = @command + ') AS Key_Table ON Extern_Table.' + @unique_key_col_name + ' = Key_Table.[KEY]';
-- ORDER BY
SET @command = @command + ' ORDER BY Key_Table.Rank DESC';
EXEC (@command);
ENDCREATE PROCEDURE fulltext_search_allTables
@criterias NVARCHAR(4000),
@largeScope BIT = 1,
@rowsToReturn INTEGER = -1
AS
DECLARE
@table_id INTEGER,
@table_name SYSNAME,
@column_id INTEGER,
@column_name SYSNAME;
DECLARE curseur CURSOR FOR SELECT DISTINCT table_name FROM fulltext_indexedcolumns;
BEGIN
IF EXISTS(SELECT * FROM Information_Schema.tables WHERE Table_Name = '#fulltext_results')
DELETE FROM #fulltext_results;
ELSE
CREATE TABLE #fulltext_results (title VARCHAR(100), linktitle VARCHAR(100), description VARCHAR(2000), rubric VARCHAR(100), rank INTEGER);
OPEN curseur
-- Vérification des mots clés dans les critères
FETCH NEXT FROM curseur
INTO @table_name
WHILE (@@FETCH_STATUS = 0)
BEGIN
EXEC fulltext_search_table @table_name, @criterias, NULL, 1, @largeScope, @rowsToReturn
FETCH NEXT FROM curseur
INTO @table_name
END
CLOSE curseur
DEALLOCATE curseur
SELECT * FROM #fulltext_results ORDER BY rank DESC;
ENDXVI. Questionnement full-text au travers de fichiers▲
Fichiers contenus dans la base de données
Pour indexer des fichiers en les stockant dans la base de données, il est nécessaire de les inclure dans des colonnes de type « image ». Pour la recherche full-text, il sera cependant nécessaire de spécifier une autre colonne qui servira à indiquer quel type de document en stocker pour chaque ligne. La recherche s'effectuera selon la manière présentée précédemment.
Fichiers contenus dans le système de fichiers
Il est cependant possible d'effectuer le questionnement sur des fichiers contenus directement dans le système de fichiers classiques. On peut effectuer deux types de questionnement sur des fichiers : - Questionnement sur les propriétés (auteur, date de création, sujet…) - Questionnement full-text sur le contenu. Par exemple :
SELECT Files.FileName, Files.Size
FROM OpenQuery(MyLinkedServer,
'SELECT FileName, Size
FROM SCOPE('' "c:\" '')
WHERE CONTAINS(''"SQL Server" NEAR() TEXT'')
AND FileName LIKE ''%.doc%'' ') > 0 AS Filessp_addlinkedserver permet de créer un serveur lié, c'est-à-dire qui autorise les accès distribués. Ce serveur lié est utilisé par OpenQuery comme on peut le voir dans le code précédent.
OpenQuery permet d'utiliser une source de données. Il peut s'agir d'une base de données ou de fichiers traditionnels. Il est important de noter que cette procédure n'accepte pas les variables en argument.
XVII. Améliorations dans Sql Server 2005 par rapport à Sql Server 2000▲
- On peut désormais choisir les colonnes à indexer dans une table ce qui n'était pas le cas dans la version 2000.
- Les colonnes de type XML peuvent être prises en compte.
- On peut désormais choisir la langue utilisée pour l'indexation (avec l'utilisation de type noise.langue, par exemple, noise.fr).
- Les commandes Save/Restore et Attach/Detach englobent aussi les catalogues d'indexation.
XVIII. Remarques▲
- Si, lors d'une recherche, les résultats ne correspondent pas aux attentes, vérifier le contenu du fichier noise.langue. Supprimez les mots considérés comme « noirs » alors qu'il s'agit de mot utilisé fréquemment dans certaines situations. Ensuite, relancez l'indexation des données.
- Le catalogue fulltext dépend du système de collation utilisé. Ainsi, un catalogue créé sur une base de données avec une collation sensible aux accents sera lui même sensible aux accents. Il est donc important de bien choisir son système de collation dès le départ. Il n'est pas possible de configurer le catalogue fulltext pour utiliser une autre collation.
XIX. Conclusion▲
Comme on a pu le voir tout au long de cet article, l'indexation fulltext est simple à mettre en place. On notera tout de même que lors d'une recherche, ce système n'est pas capable de « remarquer » lorsqu'il y a une erreur de frappe (inversion de lettres) ou une erreur au niveau de l'orthographe. Pour cela, je vous renvoie vers l'article suivant: https://sqlpro.developpez.com/cours/indextextuelle/
Merci à SqlPro pour la relecture de l'article.